Data Synchronization
Napkin friends, from near and far, it’s time for another napkin problem!
As always, consult sirupsen/napkin-math to solve today’s problem, which has all the resources you need. Keep in mind that with napkin problems you always have to make your own assumptions about the shape of the problem.
Since last time, I’ve added compression and hashing numbers to the napkin math table. Plenty more I’d like to see, happy to receive help by someone eager to write some Rust!
About a month ago I did a little pop-up lesson for some kids about competitive programming. That’s the context where I did my first napkin math. One of the most critical skills in that environment is to know ahead of time whether your solution will be fast enough to solve the problem. Was fun to prepare for the lesson, as I haven’t done anything in that space for over 6 years. I realized it’s influenced me a lot.
We’re on the 8th newsletter now, and I’d love to receive feedback from all of you (just reply directly to me here). Do you solve the problems? Do you just enjoy reading the problems, but don’t jot much down (that’s cool)? Would you prefer a change in format (such as the ability to see answers before the next letter)? Do you find the problems are not applicable enough for you, or do you like them?
Problem 8
There might be situations where you want to checksum data in a relational database. For example, you might be moving a tenant from one shard to another, and before finalizing the move you want to ensure the data is the same on both ends (to protect against bugs in your move implementation).
Checksumming against databases isn’t terribly common, but can be quite useful for sanity-checking in syncing scenarios (imagine if webhook APIs had a cheap way to check whether the data you have locally is up-to-date, instead of fetching all the data).
We’ll imagine a slightly different scenario. We have a client (web browser with local storage, or mobile) with state stored locally from table. They’ve been lucky enough to be offline for a few hours, and is now coming back online. They’re issuing a sync to get the newest data. This client has offline-capabilities, so our user was able to use the client while on their offline journey. For simplicity, we imagine they haven’t made any changes locally.
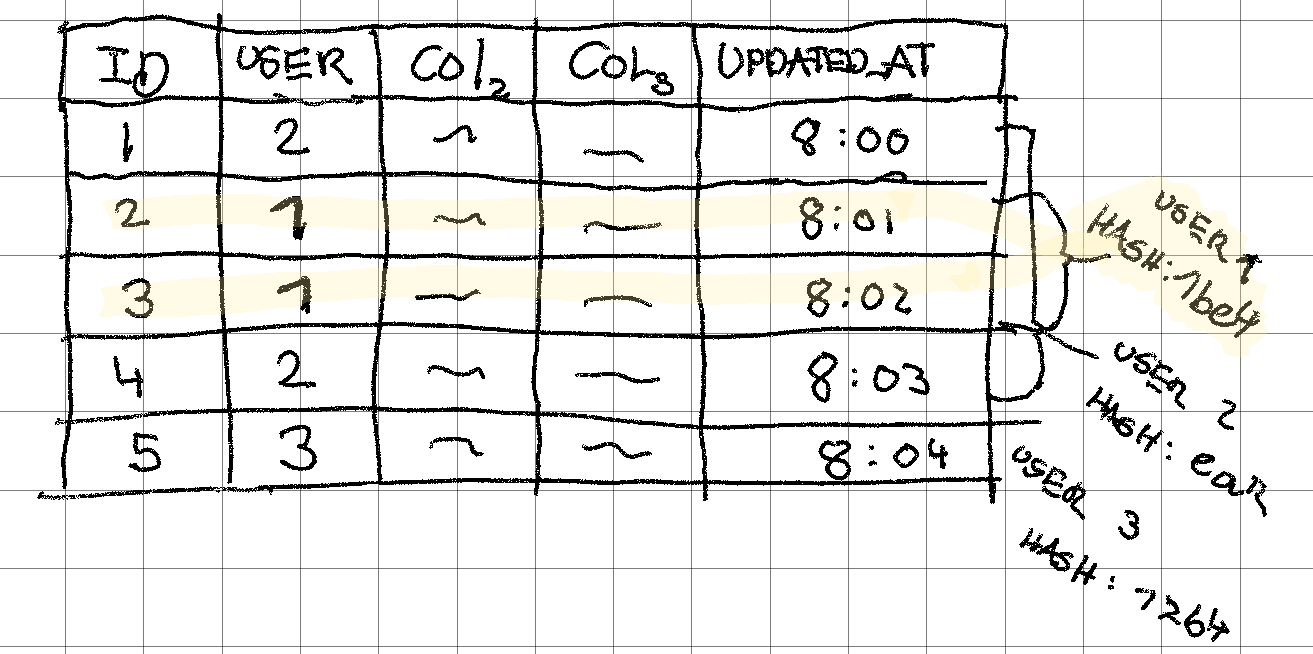
The query behind an API might look like this (in reality, the query would look more like this):
SELECT SHA1(table.updated_at) FROM table WHERE user_id = 1
The user does the same query locally. If the hashes match, user is already synced!
If the local and server-side hash don’t match, we’d have to figure out what’s happened since the user was last online and send the changes (possibly in both directions). This can be useful on its own, but can become very powerful for syncing when extended further.
(A) How much time would you expect the server-side query to take for 100,000 records that the client might have synced? Will it have different performance than the client-side query?
(B) Can you think of a way to speed up this query?
(C) This is a stretch question, but it’s fun to think about the full syncing scenario. How would you figure out which rows haven’t synced?
If you find this problem interesting, I’d encourage you to watch this video (it would help you answer question (C) if you deicde to give it a go).
Answer is available in the next edition.
Answer to Problem 7
In the last problem we looked at revision history (click it for more detail). More specifically, we looked at building revision history on top of an existing relational database with a simple composite primary key design: (id, version) with a full duplication of the row each time it changes. The only thing you knew was that the table was updating roughly 10 times per second.
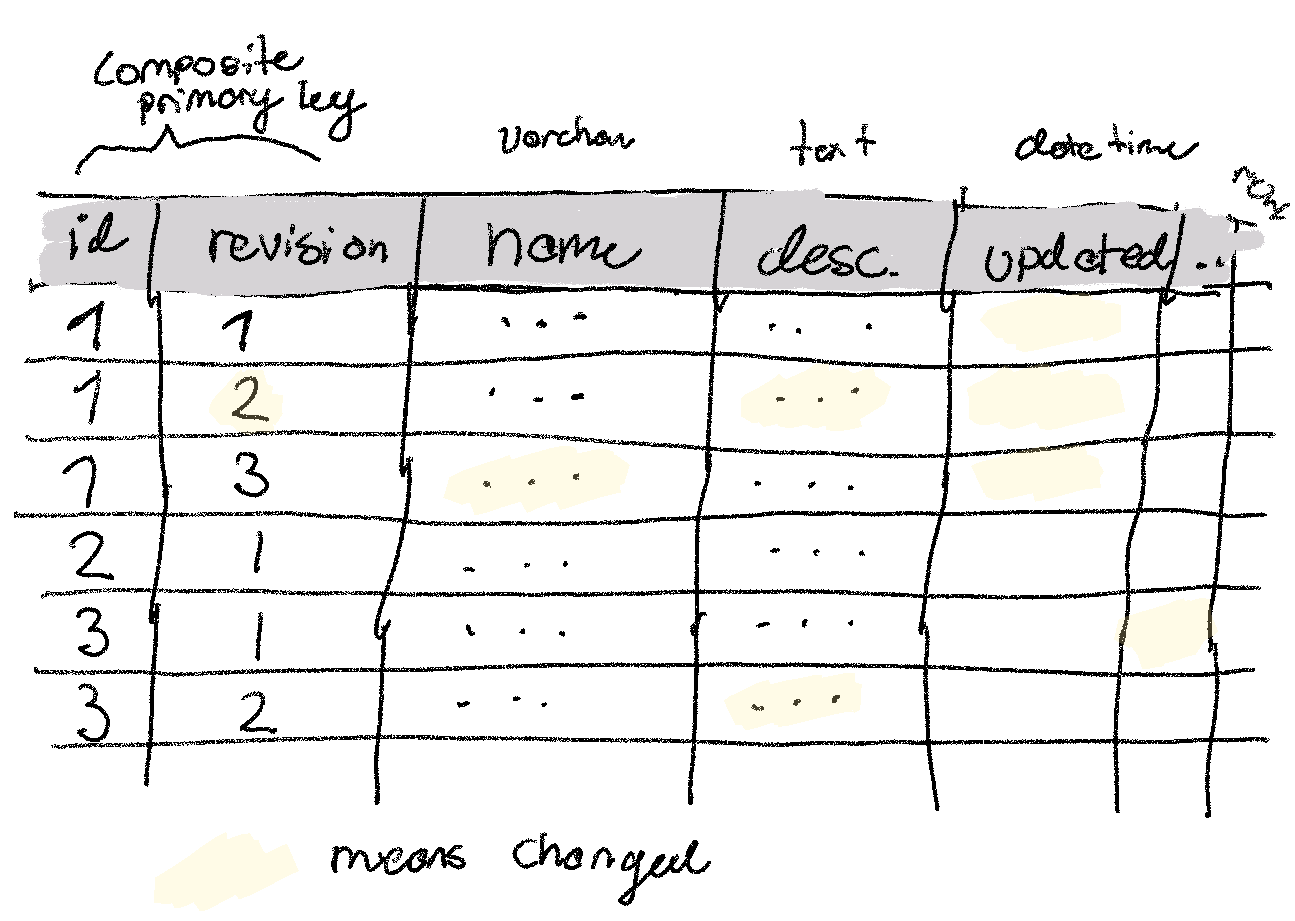
(a) How much extra storage space do you anticipate this simple scheme would require after a month? A year? What would this cost on a standard cloud provider?
The table we’re operating on was called products. Let’s assume somewhere around 256 bytes per product (some larger, some smaller, biggest variant being the product description). Each update thus generates 2^8 = 256 bytes. We can extrapolate out to a month: 2^8 bytes/update * 10 update * 3600 seconds/hour * 24 hour/day * 30 day/month ~= 6.5 Gb/month. Or ~80Gb per year. Stored on SSD on a standard Cloud provider at $0.01/Gb, that’ll run us ~$8/month.
(b) Based on (a), would you keep storing it in a relational database, or would you store it somewhere else? Where? Could you store it differently more efficiently without changing the storage engine?
For this table, it doesn’t seem crazy—especially if we look at it as a cost-only problem. Main concern that comes to mind here to me is that this will decrease query performance, at least in MySQL. Every time you load a record, you’re also loading adjacent records as you draw in the 16KiB page (as determined by the primary key).
Accidental abuse would also become a problem. You might have a well-meaning merchant with a bug in a script that causes them to update their products 100/times second for a while. Do you need to clear these out? Does it permanently decrease their performance? Limitations in the number of revisions per product would likely be a sufficient upper-case for a while.
If we moved to compression, we’d likely get a 3x storage-size decrease. That’s not too significant, and incurs a fair amount of complexity.
If you, for e.g. one of the reasons above, needed to move to another engine, I’d likely base the decision on how often it needs to be queried, and what types of queries are required on the revisions (hopefully you don’t need to join on them).
The absolute simplest (and cheapest) would be to store it on GCS/S3, wholesale, no diffs — and then do whatever transformations necessary inside the application. I would hesitate strongly to move to something more complicated than that unless absolutely necessary (if you were doing a lot of version syncing, that might change the queries you’re doing substantially, for example).
Do you have other ideas on how to solve this? Experience? I’d love to hear from you!