Composite Primary Keys
Napkin friends, from near and far, it’s time for napkin problem number 5! If you are wondering why you’re receiving this email, you likely watched my talk on napkin math and decided to sign up for some monthly practise.
Since last, in the napkin-math repository I’ve added system call
overhead. I’ve been also been working on io_uring(2) disk
benchmarks, which leverage a new Linux API from 5.1
to queue I/O sys-calls (in more recent kernels, network is also supported, it’s under active development). This
avoids system-call overhead and allows the kernel to order them as efficiently
as it likes.
As always, consult sirupsen/napkin-math for resources and help to solve this edition’s problem! This will also have a link to the archive of past problems.
Napkin Problem 5
In databases, typically data is ordered on disk by some key. In relational
databases (and definitely MySQL), as an example, the data is ordered by the
primary key of the table. For many schemas, this might be the AUTO_INCREMENT id column. A good primary key is one that stores together records that are
accessed together.
We have a products table with the id as the primary key, we might do a query
like this to fetch 100 products for the api:
SELECT * FROM products WHERE shop_id = 13 LIMIT 100
This is going to zig-zag through the product table pages on disk to load the 100
products. In each page, unfortunately, there are other records from other shops (see illustration below).
They would never be relevant to shop_id = 13. If we are really unlucky, there may be
only 1 product per page / disk read! Each page, we’ll assume, is 16 KiB (the
default in e.g. MySQL). In the worst case, we could load 100 * 16 KiB!
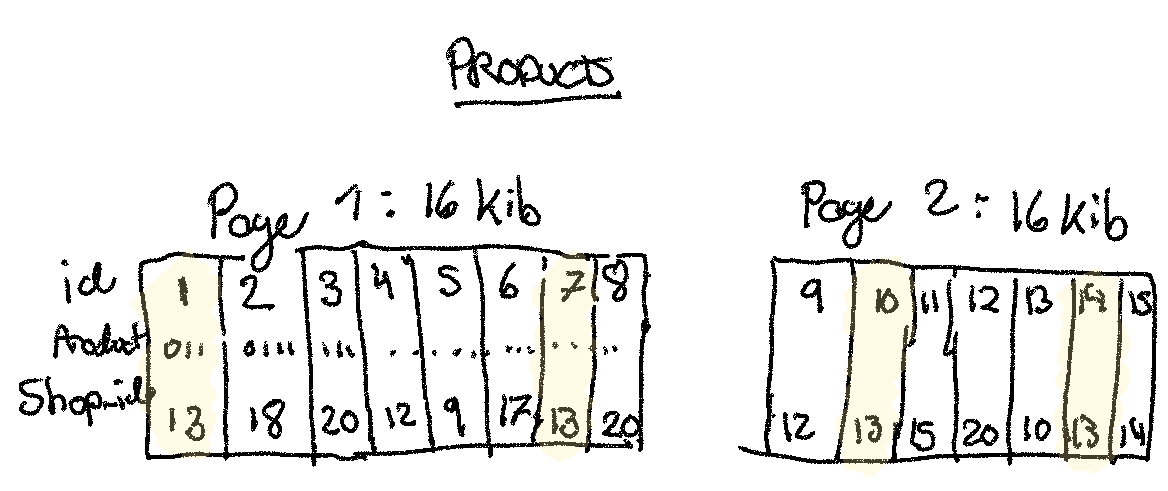
(1) What is the performance of the query in the worst-case, where we load only one product per page?
(2) What is the worst-case performance of the query when the pages are all in memory cache (typically that would happen after (1))?
(3) If we changed the primary key to be (shop_id, id), what would the
performance be when (3a) going to disk, and (3b) hitting cache?
I love seeing your answers, so don’t hesitate to email me those back!
Answer is available in the next edition.
Answer to Problem 4
The question can be summarized as: How many commands-per-second can a simple, in-memory, single-threaded data-store do? See the full question in the archives.
The network overhead of the query is ~10us (you can find this number in
sirupsen/napkin-math). We expect each memory read to be random, so the
latency here is 50ns. This goes out the wash with the networking overhead, so
with a single CPU, we estimate that we can roughly do 1s/10us = 1 s / 10^-5 s = 10^5 = 100,000 commands per second, or about 10x what the team was seeing.
Something must be wrong!
Knowing that, you might be interested to know that Redis 6 rc1 was just released with threaded I/O support.
You might also like...