Using checksums to verify syncing 100M database records
I’ve been working with Datafold on an open-source implementation. Check out datafold/data-diff!
A common problem you’ve almost certainly faced is to sync two datastores. This problem comes up in numerous shapes and forms: Receiving webhooks and writing them into your datastore, maintaining a materialized view, making sure a cache reflects reality, ensure documents make it from your source of truth to a search index, or your data from your transactional store to your data lake or column store.
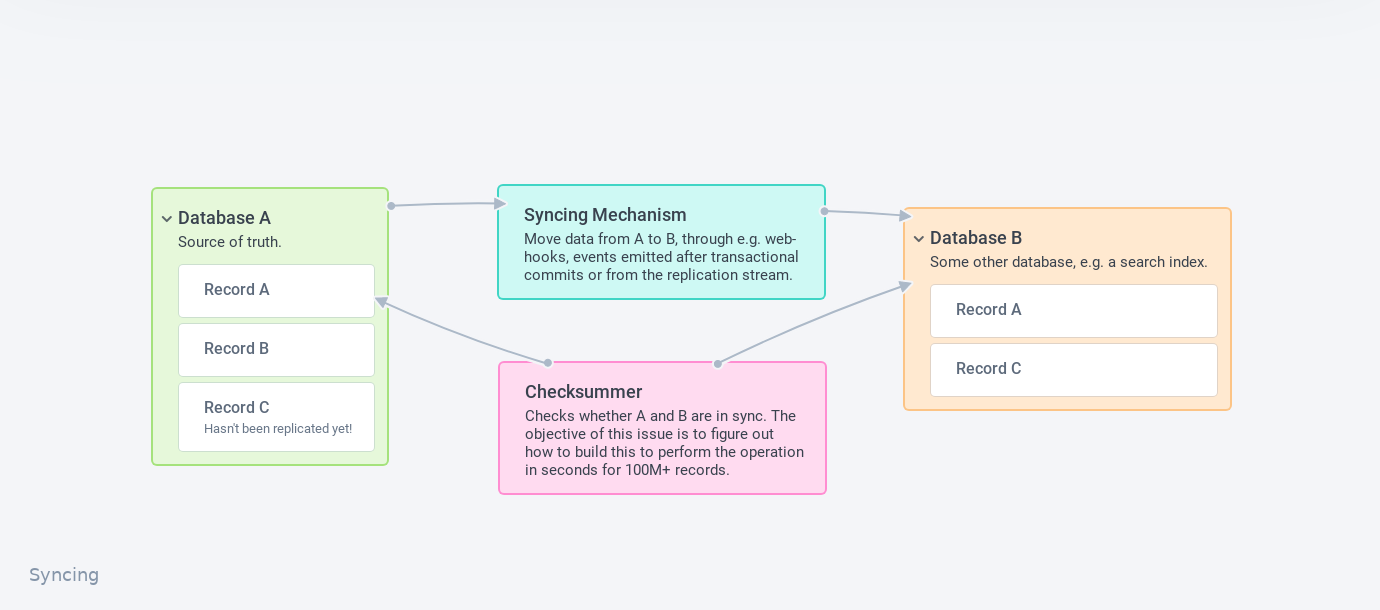
If you’ve built such a system, you’ve almost certainly seen B drift out of sync. Building a completely reliable syncing mechanism is difficult, but perhaps we can build a checksumming mechanism to check if the two datastores are equal in a few seconds?
In this issue of napkin math, we look at implementing a solution to check whether A and B are in sync for 100M records in a few seconds. The key idea is to checksum an indexed updated_at column and use a binary search to drill down to the mismatching records. All of this will be explained in great detail, read on!
Why are syncing mechanisms unreliable?
If you are firing the events for your syncing mechanism after a transaction occurs, such as enqueuing a job, sending a webhook, or emit a Kafka event, you can’t guarantee that it actually gets sent after the transaction is committed. Almost certainly part of pipeline into database B is leaky due to bugs: perhaps there’s an exception you don’t handle, you drop events on the floor above a certain size, some early return, or deploys lose an event in a rare edge case.
But even if you’re doing something that’s theoretically bullet-proof, like using the database replication logs through Debezium, there’s still a good chance a bug somewhere in your syncing pipeline is causing you to lose occasional events. If theoretical guarantees were adequate, Jepsen wouldn’t uncover much, would it? A team I worked with even wrote a TLA+ proof, but still found bugs with a solution like the one I describe here! In my experience, a checksumming system should be part of any syncing system.
It would seem to me that building reliable syncing mechanisms would be easier if databases had a standard, fast mechanism to answer the question: “Does database A and B have all the same data? If not, what’s different?” Over time, as you fix your bugs, it will of course happen more rarely, but being able to guarantee that they are in sync is a huge step forward.
Unfortunately, this doesn’t exist as a user API in modern databases, but perhaps we can design such a mechanism without modifying the database?
This exploration will be fairly long. If you just want to see the final solution, scroll down to the end. This issue shows how to use napkin math to incrementally justify increasing complexity. While I’ve been thinking about this problem for a while, this is a fairly accurate representation of how I thought about the problem a few months ago when I started working on it. It’s also worth noting that when doing napkin math usually, I don’t write prototypes like this if I’m fairly confident in my understanding of the system underneath. I’m doing it here to make it more entertaining to read!
Assumptions
Let’s start with some assumptions to plan out our ‘syncing checksum process’:
- 100M records
- 1KiB per record (~100 GiB total)
We’ll assume both ends are SQL-flavoured relational databases, but will address other datastores later, e.g. ElasticSearch.
Iteration 1: Check in Batches
As usual, we will start by considering the simplest possible solution for checking whether two databases are in sync: a script that iterates through all records in batches to check if they’re the same. It’ll execute the SQL query below in a loop, iterating through the whole collection on both sides and report mismatches:
SELECT * FROM `table`
ORDER BY id ASC
LIMIT @limit OFFSET @offset
Let’s try to figure out how long this would take: Let’s assume each loop is querying the two databases in parallel and our batches are 10,000 records (10 MiB total) large:
- In MySQL, reading 10 MiB off SSD at 200 us/MiB will take ~2ms. We assume this to be sequential-ish, but this is not entirely true.
- Serializing and deserializing the MySQL protocol at 5 ms/MiB, for a total of ~2* 50ms = 100ms.
- Network transfer at 10 ms/MiB, for a total of ~100ms.
We’d then expect each batch to take roughly ~200ms. This would bring our theoretical grand total for this approach to 200 ms/batch * (100M / 10_000) batches ~= 30min.
To test our hypothesis against reality, I implemented this to run locally for the first 100 of the 10,000 batches. In this local implementation, we won’t incur the network transfer overhead (we could’ve done this with Toxiproxy). Without the network overhead, we expect a query time in the 100ms ballpark. Running the script, I get the following plot:
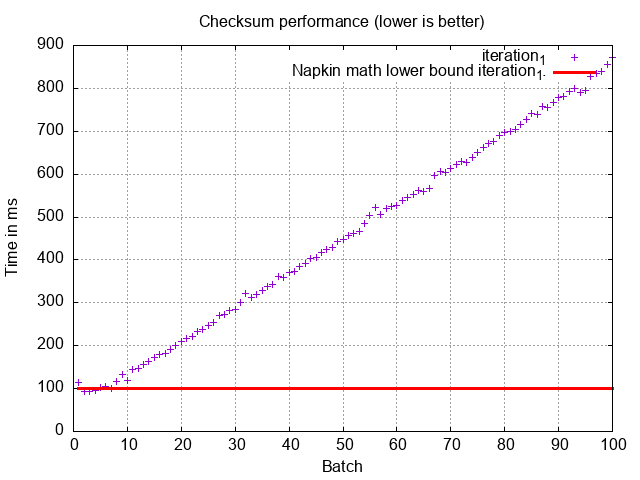
Ugh. The real performance is pretty far from our napkin math lower bound estimate. What’s going on here?
There’s a fundamental problem with our napkin math. Only the very first batch will read only ~10 MB off of the SSD in MySQL. OFFSET queries will read through the data before the offset, even if it only returns the data after the offset! Each batch takes 3-5ms more than the last, which lines up well with reading another 10 MiB per batch from the increasing offset.
This is the reason why OFFSET-based pagination causes so much trouble in production systems. If we take the area under the graph here and extend to the 10,000 batches we’d need for our 100M records, we get a ~3 day runtime.
Iteration 2: Outsmarting the optimizer
As OFFSET will scan through all these 1 KiB records, what if we scanned an index instead? It’ll be much smaller to skip 100,000s of records on an index where each record only occupies perhaps 64 bit. It’ll still grow linearly with the offset, but passing the previous batch’s 10,000 records is only 10 KiB which would only take a few hundred microseconds to read.
You’d think the optimizer would make this optimization itself, but it doesn’t. So we have to do it ourselves:
SELECT * FROM `table`
WHERE id > (SELECT id FROM table LIMIT 1 OFFSET @offset)
ORDER BY id ASC
LIMIT 10000;
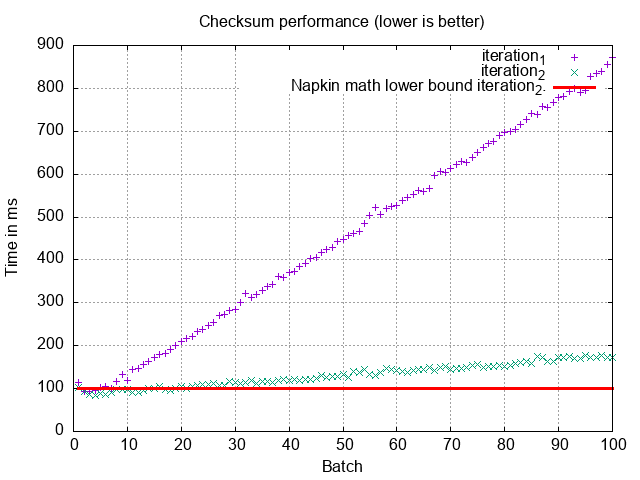
It’s better, but just not by enough. It just delays the inevitable scanning of lots of data to find these limits. If we interpolate how long this’d take for 10,000 batches to process our 100M records, we’re still talking on the order of 14 hours. The 128x speedup doesn’t carry through, because it only applies to the MySQL part. Network transfer is still a large portion of the total time!
Either way, if you have some OFFSET queries lying around in your codebase, you might want to consider this optimization.
Iteration 3: Parallelization
This seems like an embarrassingly parallel problem: Can’t we just run 100 batches of 10,000 records in parallel? Can the database support that? Since we can pre-compute all the LIMITs and OFFSETs up front, let’s abuse that?
This seems kind of difficult to do the napkin math on. Typically when that’s the case, I try to solve the problem backwards: Fundamentally, the machine can read sequential SSD at 4 GiB/s, which would be an absolute lower bound for how fast the database can work. The dataset is 100 GiB, as we established in the beginning.
If we’re using our optimization from iteration 2, then our queries are on average processing 50M * 64 bit for the sub-query, and the 10 MiB of returned data on top. That’s a total of ~400 MiB. So for our 10,000 batches, that’s 4.2 TB of data we will need to munch through with this query. We can read 1 GiB from SSD in 200ms, so that’s 14 minutes in total. That would be the absolute lowest bound, assuming essentially zero overhead from MySQL and not taking into consideration serialization, network, etc.
This also assumes the MySQL instance is doing nothing but serving our query, which is unrealistic. In reality, we’d dedicate maybe 10% of capacity to these queries, which puts us at 2 hours. Still faster, but a far cry from our hope of seconds or minutes. Buuh.
Iteration 4: Dropping OFFSET
It’s starting to seem like trouble to use these OFFSET queries, even as sub-queries. We held on to it for a while, because it’s nice and easy to reason about, and means the queries can be fired off in parallel. We also held on to it for a while to truly show how awful these types of queries are, so hopefully you think twice about using it in a production query again!
If we change our approach to maintain max(id) from the last batch, we can simply change our loop’s query to:
SELECT * FROM `table`
WHERE id > @max_id_from_last_batch
ORDER BY id ASC
LIMIT 10000;
This curbed the linear growth!
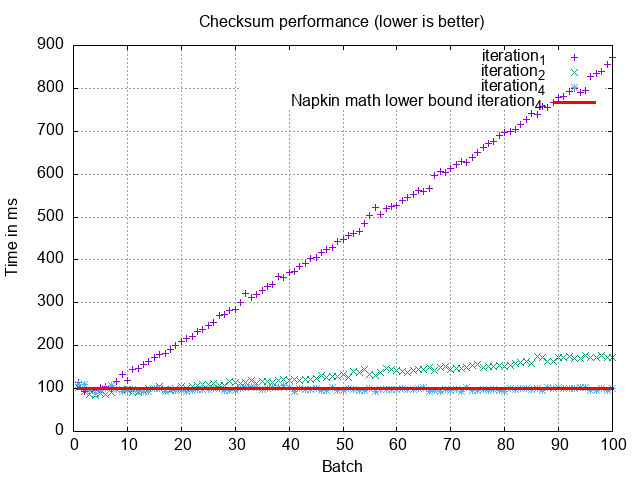
Now MySQL can use its efficient primary key index to do ~6 SSD seeks on id and then scan forward. This means we only process and serialize 10 MiB, putting our napkin math consistently around 100ms per batch as in the original estimate in iteration 1. That means this solution should finish in about half an hour! However, we learned in the previous iteration that we are constrained by only taking 10% of the database’s capacity, so as calculated from iteration 3, we’re back at 2 hours..
We fundamentally need an approach that handles less data, as the serialization and network time is the primary reason why the integrity checking is now slow.
Iteration 5: Checksumming
If we want to handle less data, we need to have some way to fingerprint or checksum each record. We could change our query to something along the lines of:
SELECT MD5(*) FROM table
WHERE id > @max_id_from_last_batch
ORDER BY id ASC
LIMIT 10000;
If there’s a mismatch, we simply revert to iteration 4 and find the rows that mismatch, but we have to scan far less data as we can assume the majority of it lines up.
Before moving on, let’s see whether the napkin math works out:
- Reading 10 MiB off SSD at 200 us/MiB will take ~2ms.
- Hashing 10 MiB at 5 ms/MiB will take ~50ms.
- 6 SSD seeks to find the ID at 100 us/seek will take ~600 us.
- 1 network round-trip at 250 us of the 16 byte hash.
This is promising! In reality, it requires a little more SQL wrestling, for MySQL:
SELECT max(id) as max_id, MD5(CONCAT(
MD5(GROUP_CONCAT(UNHEX(MD5(COALESCE(t.col_a))))),
MD5(GROUP_CONCAT(UNHEX(MD5(COALESCE(t.col_b))))),
MD5(GROUP_CONCAT(UNHEX(MD5(COALESCE(t.col_c)))))
)) as checksum FROM (
SELECT col_a, col_b, col_c FROM `table`
WHERE id > @max_id_from_last_batch
LIMIT 10000
) t
We seem to match our napkin math well:
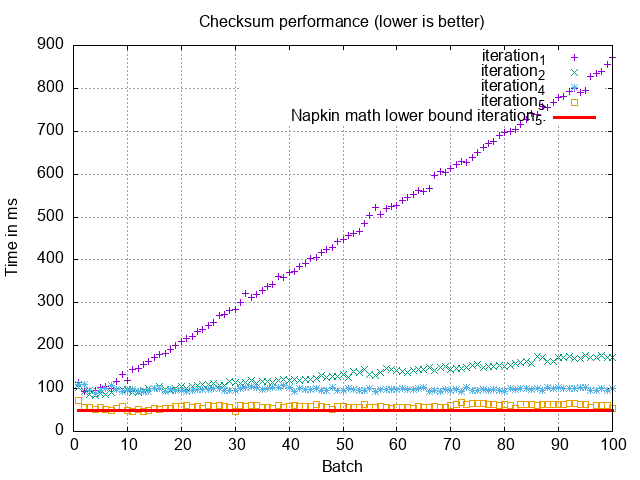
This is the place to stop if you want to err on the side of safety. This is how we verify the integrity when we move shops between shards at Shopify, which is what this approach is inspired by. However, to push performance further we need to get rid of some of this inline aggregation and hashing which eats up all our performance budget. At 50ms/batch, we’re still at ~10 minutes to complete the checksumming of 100M records.
Iteration 6: Checksumming with updated_at
Many database schemas have an updated_at column which contains the timestamp where the record was last updated. We can use this as the checksum for the row, assuming that the granularity of the timestamp is sufficient (in many cases, granularity is only seconds, but e.g. MySQL supports fractional second granularity).
A huge performance advantage of this is that we can use an index on updated_at, and no longer read and hash the full 1 KiB row! We now only need to read and hash the 64 bit timestamps. This cuts down on the data we need to read per batch from 10 MiB to 80Kb!
Additionally, instead of using the checksum, we can simply use a sum of the updated_at. This has the nice property of being much faster, and that we don’t necessarily need the same sort order in the other database. This will become very important if you’re doing checksumming against a database that might not store in the same order easily, e.g. ElasticSearch/Lucene.
Won’t summing so many records overflow? Nah, UNIX timestamp right now are approaching 32 bits, which means we can sum around 2^32 ~= 4 billion without overflowing. Isn’t a sum a poor checksum? Sure, a hash is safer, but this is not crypto, just simple checksumming. It seems sufficient to me. Might not be in your case, in which case you can use MD5, SHA1, or CRC32 or use the solution from iteration 5.
We still need an offset, as we can’t rely on ids increasing by exactly 1 as ids may have been deleted:
SELECT max(id) as max_id,
SUM(UNIX_TIMESTAMP(updated_at)) as checksum
FROM `table` WHERE id < (
SELECT id FROM `table`
WHERE id > @max_id_from_last_batch
LIMIT 1 OFFSET 10000
) AND id > @max_id_from_last_batch
Let’s take inventory:
- Reading 80 KiB of the
updated_atindex off SSD at 1 us/8 KiB will take ~50 us. - Summing 80 KiB at 5 ns/64 bytes will take ~50 us.
- 6 SSD seeks to find the ID at 100 us/seek will take ~600 us.
- 1 network round-trip at 250 us of the 16 byte hash.
In theory, this query should take milliseconds! In reality, there’s overhead involved, and we can’t assume in MySQL that reads are completely sequential as fragmentation occurs on indexes and the primary key.
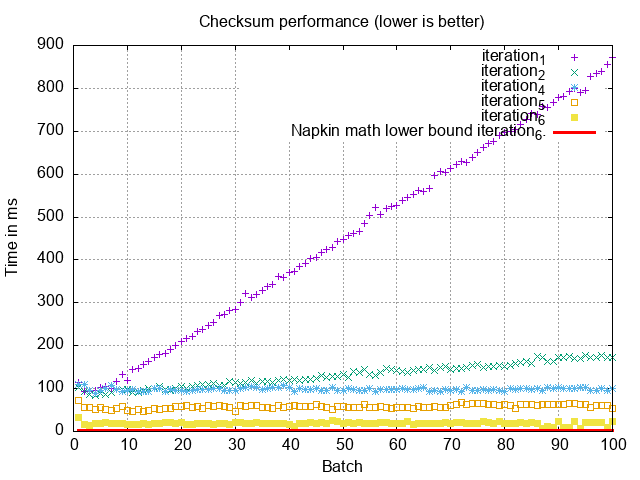
Without the first iteration:
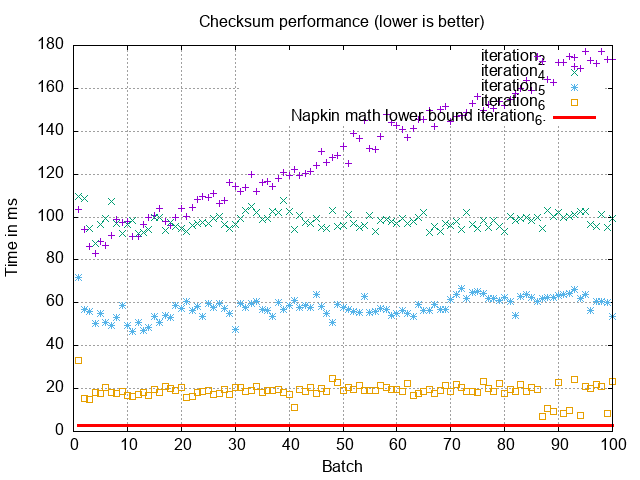
What’s going on? We were expecting single-digit milliseconds, but we’re seeing 20ms per batch! Something is wrong. 20ms per batch still means our total checksumming time is 3 min. We’ve got more work to do.
Iteration 7: Using the right indexes
An EXPLAIN reveals we’re using the PRIMARY key for both queries, which means we’re loading these entire 1 KiB records, not just the 64 bit off the updated_at index.
Using the indexes on (id) and (id, updated_at) we need to scan much less data. It’s counter-intuitive to create an index on id, since the primary key already has an “index.” The problem with that index is that it also holds all the data. It’s not just the 64-bit id. You’re scanning over a lot of records. Indexes structured in this way are great in a lot of cases to minimize seeks (it’s called a clustered index), but problematic in others. Since these indexed already existed, this is another example of the MySQL optimizer not making the right decision for us. Forcing these indexes our query becomes:
SELECT max(id) as max_id,
SUM(UNIX_TIMESTAMP(updated_at)) as checksum
FROM `table`
FORCE INDEX (`index_table_id_updated_at`)
WHERE id < (
SELECT id
FROM `table`
FORCE INDEX (`index_table_id`)
WHERE id > @max_id_from_last_batch
LIMIT 1 OFFSET 10000
) AND id > @max_id_from_last_batch
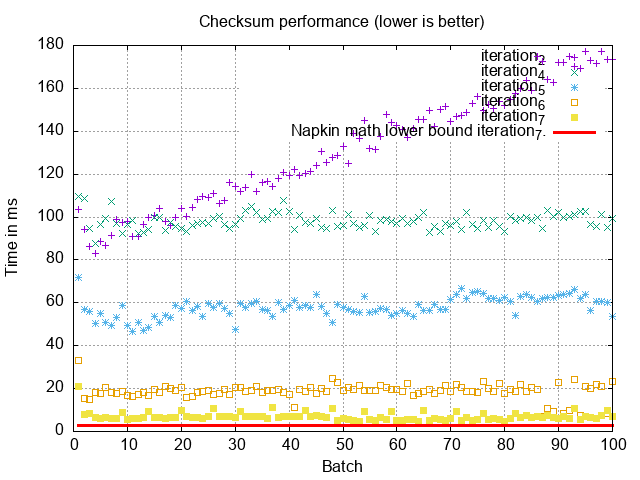
Nice, that’s quite a bit faster, let’s remove the previous iterations to make it a little easier to see the graphs we care about now:
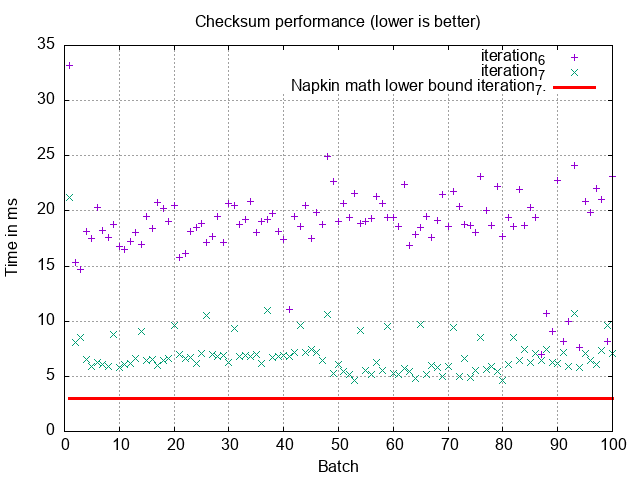
5ms per batch is close to the theoretical floor we established in iteration 6! To checksum our full 100M records, this would take 50 seconds. We aren’t going to get much better than this as far as I can tell without modifying MySQL or pre-computing the checksums with e.g. triggers.
What about database constraints? Will this take up our whole database as we had trouble with in early iterations? Fortunately, this solution is much less I/O heavy than our early iterations. We need to read 2-3 GiB of indexes in total to serve these queries. Spread over 50 seconds we’re talking 10s of MiB/s, so we should be good.
The last trick to consider is to not checksum check all records in a loop. We could add another condition to only checksum records created in the past few minutes updated_at >= TIMESTAMPADD(MINUTE, -5, NOW()), while doing full checks only periodically. You would likely want to also ignore records created in the past few seconds, to allow replication to occur: updated_at <= TIMESTAMPADD(SECOND, 30, NOW()). We do still want our fast way to scan all records, as this is by far the safest, and for a database with 10,000s of changes per second, that also needs to be fast. The full check is also paramount when we bring up new databases and during development.
What do we do on a mismatch?
Great, so we can now check whether batches are the same across two SQL databases quickly. We could build APIs for this to avoid users querying each other’s database. But what do we do when we have a mismatch?
We could send every record in the batch, but those queries are still fairly taxing. Especially if we are checksumming batches of 100,000s of records to optimize the checksumming performance.
We can perform a binary search: If we are checksumming 100,000 records and encounter a mismatch, we cut the records into two queries checksumming 50,000 records each. Whichever one has the mismatch, we slice them in two again until you find the record(s) that don’t match!
This approach is very similar to the Merkle tree synchronization I described in problem 9. You can think of the approach we’ve landed on here as Merkle tree synchronization between two databases, but it’s simpler just to think of it as checksumming in batches. This approach is also quite similar to how rsync works.
What about other types of databases?
While we covered SQL-to-SQL checksumming here, I’ve implemented a prototype of the method described here to check whether all records from a MySQL database make it to an ElasticSearch cluster. ElasticSearch, just like MySQL, is able to sum updated_at fast. Most databases that support any type of aggregation should work for this. Datastores like Memcached or Redis would require more thought, as they don’t implement aggregations. This would be an interesting use-case for checking the integrity of a cache. It would be possible to do something, of course, but it would require core changes to them.
Hope you enjoyed this. I think this is a neat pattern that I hope to see more adoption for, and perhaps even some databases and APIs adopt. Wouldn’t it be great if you could check if all your data was up-to-date just about everywhere with just a couple of API calls exchanging hashes?
P.S. A few weeks ago this newsletter hit 1,000 subscribers. I’m really grateful to all of you for listening in! It’s been quite fun to write these posts. It’s my favourite kind of recreational programming.
The napkin math reference has also recently been extensively updated, in part to support this issue.