When To Write a Simulator
My rule for when to write a simulator:
Simulate anything that involves more than one probability, probabilities over time, or queues.
Anything involving probability and/or queues you will need to approach with humility and care, as they are often deceivingly difficult: How many people with their random, erratic behaviour can you let into the checkout at once to make sure it doesn’t topple over? How many connections should you allow open to a database when it’s overloaded? What is the best algorithm to prioritize asynchronous jobs to uphold our SLOs as much as possible?
If you’re in a meeting discussing whether to do algorithm X or Y with this nature of problem without a simulator (or amazing data), you’re wasting your time. Unless maybe one of you has a PhD in queuing theory or probability theory. Probably even then. Don’t trust your intuition for anything the rule above applies to.
My favourite illustration of how bad your intuition is for these types of problems is the Monty Hall problem:
Suppose you’re on a game show, and you’re given the choice of three doors: Behind one door is a car; behind the others, goats. You pick a door, say No. 1, and the host, who knows what’s behind the doors, opens another door, say No. 3, which has a goat. He then says to you, “Do you want to pick door No. 2?”
Is it to your advantage to switch your choice?

Against your intuition, it is to your advantage to switch your choice. You will win the car twice as much if you do! This completely stumped me. Take a moment to think about it.
I frantically read the explanation on Wikipedia several times: still didn’t get it. Watched videos, now I think that.. maybe… I get it? According to Wikipedia, Erdős, one of the most renowned mathematicians in history also wasn’t convinced until he was shown a simulation!
After writing my simulation, however, I finally feel like I get it. Writing a simulation not only gives you a result you can trust more than your intuition but also develops your understanding of the problem dramatically. I won’t try to offer an in-depth explanation here, click the video link above, or try to implement a simulation — and you’ll see!
# https://gist.github.com/sirupsen/87ae5e79064354b0e4f81c8e1315f89b
$ ruby monty_hall.rb
Switch strategy wins: 666226 (66.62%)
No Switch strategy wins: 333774 (33.38%)
The short of it is that the host always opens the non-winning door, and not your door, which reveals information about the doors! Your first choice retains the 1/3 odds, but switching at this point, incorporating ‘the new information’ of the host opening a non-winning door, you improve your odds to 2/3 if you always switch.
This is a good example of a deceptively difficult problem. We should simulate it because it involves probabilities over time. If someone framed the Monty Hall problem to you you’d intuitively just say ‘no’ or ‘1/3’. Any problem involving probabilities over time should humble you. Walk away and quietly go write a simulation.
Now imagine when you add scale, queues, … as most of the systems you work on likely have. Thinking you can reason about this off the top of your head might constitute a case of good ol’ Dunning-Kruger. If Bob’s offering a perfect algorithm off the top of his head, call bullshit (unless he carefully frames it as a hypothesis to test in a simulator, thank you, Bob).
When I used to do informatics competitions in high school, I was never confident in my correctness of the more math-heavy tasks — so I would often write simulations for various things to make sure some condition held in a bunch of scenarios (often using binary search). Same principle at work: I’m much more confident most day-to-day developers would be able to write a good simulation than a closed-form mathematical solution. I once read something about a mathematician that spent a long time figuring out the optimal strategy in Monopoly. A computer scientist came along and wrote a simulator in a fraction of the time.
Using Randomness Instead of Coordination?
A few years ago, we were revisiting old systems as part of moving to Kubernetes. One system we had to adapt was a process spun up for every shard to do some book-keeping. We were discussing how we’d make sure we’d have at least ~2-3 replicas per shard in the K8s setup (for high availability). Previously, we had a messy static configuration in Chef to ensure we had a service for each shard and that the replicas spread out among different servers, not something that easily translated itself to K8s.
Below, the green dots denote the active replica for each shard. The red dots are the inactive replicas for each shard:
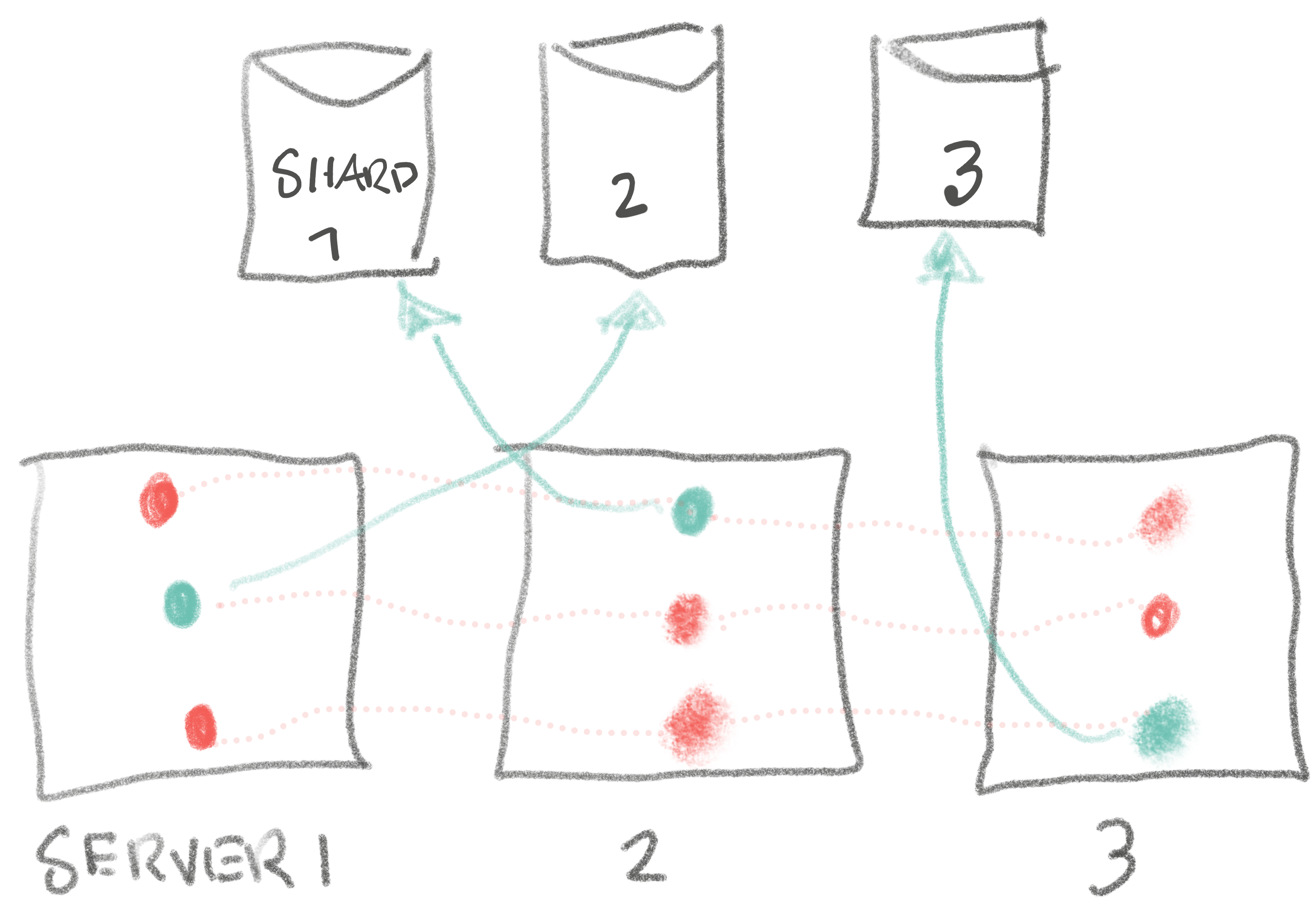
We discussed a couple of options: each process consulting some shared service to coordinate having enough replicas per shard, or creating a K8s deployment per shard with the 2-3 replicas. Both sounded a bit awkward and error-prone, and we didn’t love either of them.
As a quick, curious semi-jokingly thought-experiment I asked:
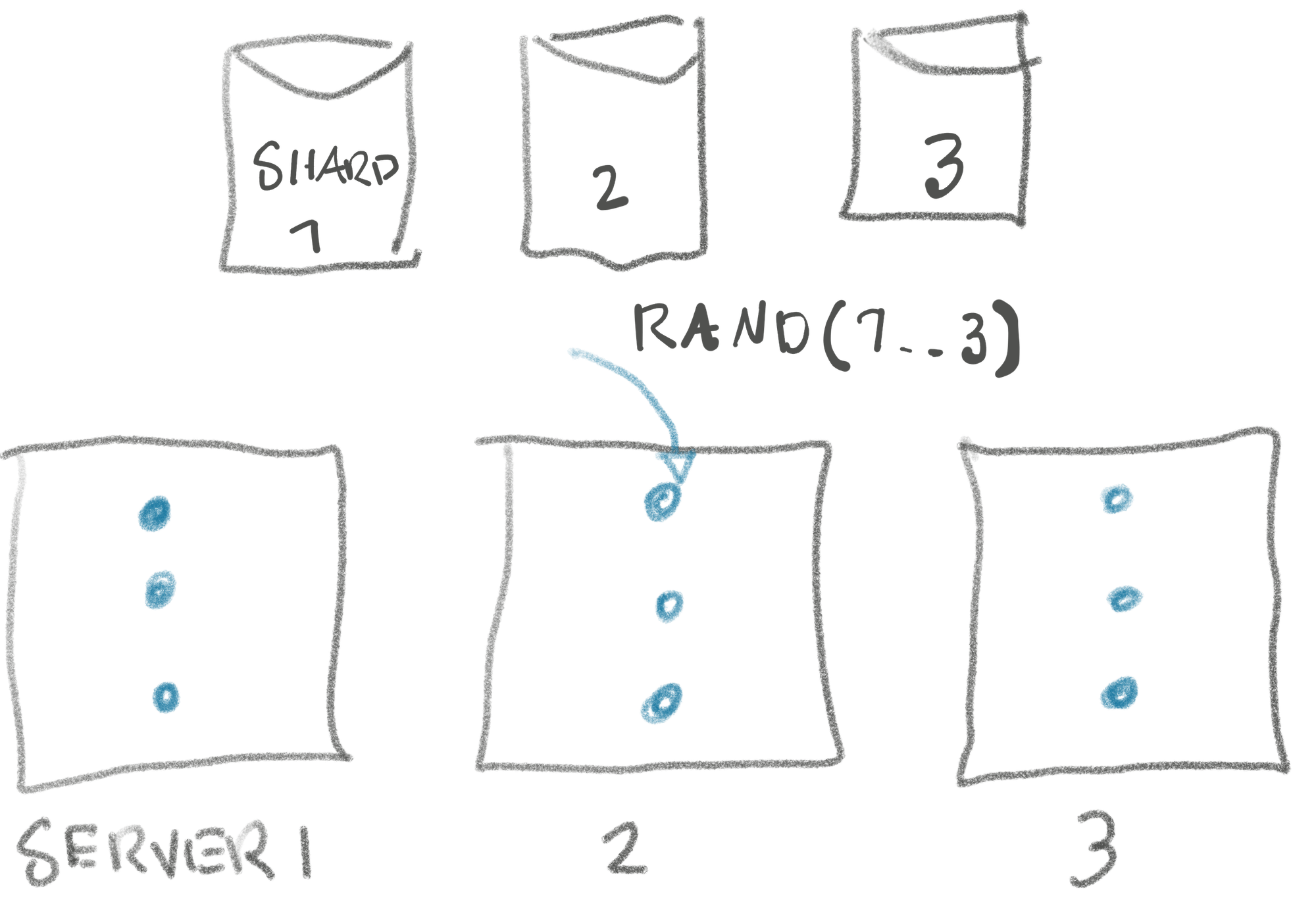
“What if each process chooses a shard at random when booting, and we boot enough that we are near certain every shard has at least 2 replicas?”
To rephrase the problem in a ‘mathy way’, with n being the number of shards:
“How many times do you have to roll an
n-sided die to ensure you’ve seen each side at leastmtimes?”
This successfully nerd-sniped everyone in the office pod. It didn’t take long before some were pulling out complicated Wikipedia entries on probability theory, trawling their email for old student MatLab licenses, and formulas soon appeared on the whiteboard I had no idea how to parse.
Insecure that I’ve only ever done high school math, I surreptitiously started writing a simple simulator. After 10 minutes I was done, and they were still arguing about this and that probability formula. Once I showed them the simulation the response was: “oh yeah, you could do that too… in fact that’s probably simpler…” We all had a laugh and referenced that hour endearingly for years after. (If you know a closed-form mathematical solution, I’d be very curious! Email me.)
# https://gist.github.com/sirupsen/8cc99a0d4290c9aa3e6c009fdce1ffec
$ ruby die.rb
Max: 2513
Min: 509
P50: 940
P99: 1533
P999: 1842
P9999: 2147
It followed from running the simulation that we’d need to boot 2000+ processes
to ensure we’d have at least 2 replicas per shard with a 99.99% probability
with this strategy. Compare this with the ~400 we’d need if we did some light
coordination. As you can imagine, we then did the napkin cost of 1600 excess
dedicated CPUs to run these book-keepers at [16,000 a month? Probably not.
Throughout my career I remember countless times complicated Wikipedia entries have been pulled out as a possible solution. I can’t remember a single time that was actually implemented over something simpler. Intimidating Wikipedia entries might be another sign it’s time to write a simulator, if nothing else, to prove that something simpler might work. For example, you don’t need to know that traffic probably arrives in a Poisson distribution and how to do further analysis on that. That will just happen in a simulation, even if you don’t know the name. Not important!
Another Real Example: Load Shedding
At Shopify, a good chunk of my time there I worked on teams that worked on reliability of the platform. Years ago, we started working on a ‘load shedder.’ The idea was that when the platform was overloaded we’d prioritize traffic. For example, if a shop got inundated with traffic (typically bots), how could we make sure we’d prioritize ‘shedding’ (red arrow below) the lowest value traffic? Failing that, only degrade that single store? Failing that, only impact that shard?
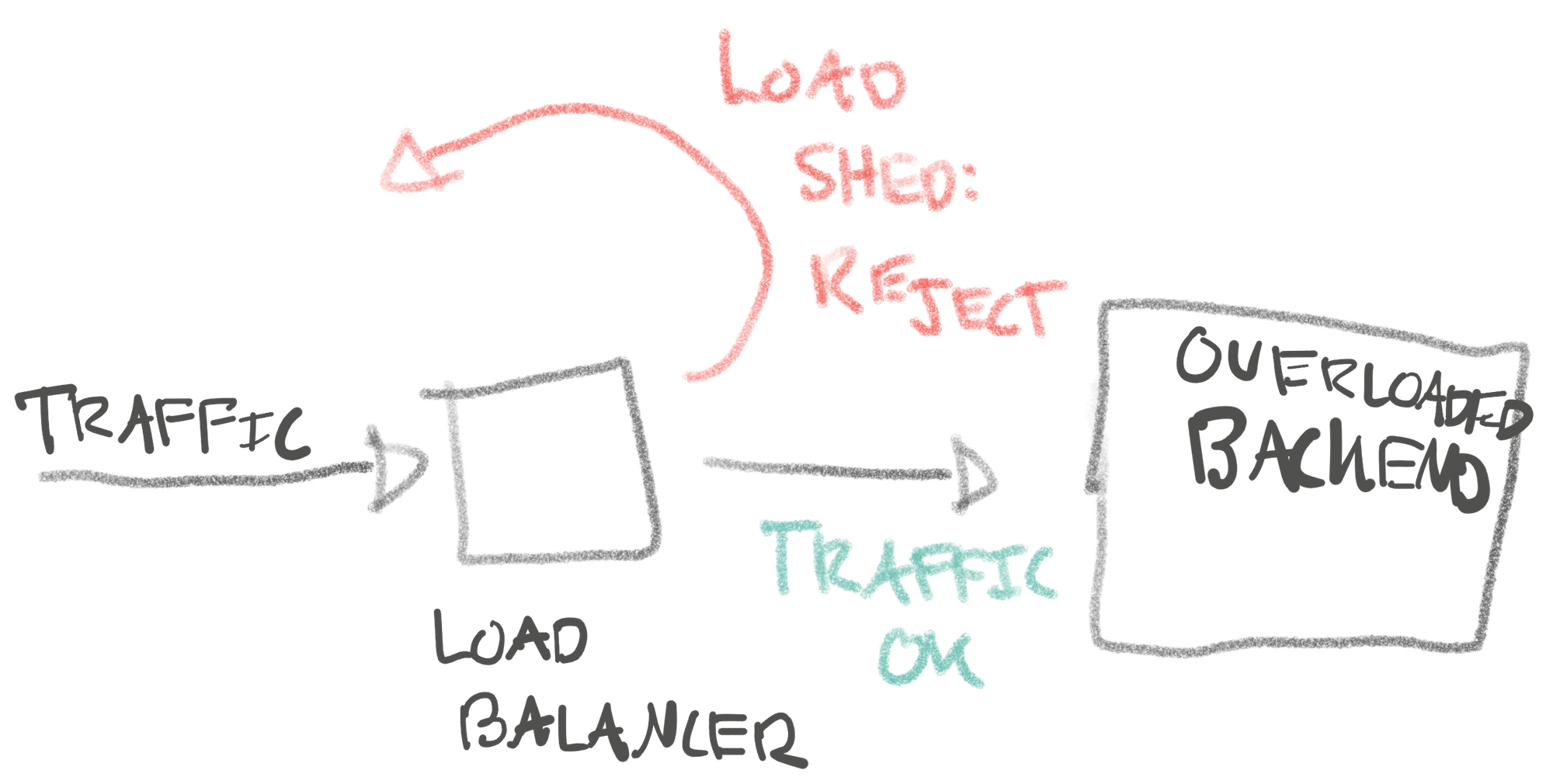
Hormoz Kheradmand led most of this effort, and has written this post about it in more detail. When Hormoz started working on the first load shedder, we were uncertain about what algorithms might work for shedding traffic fairly. It was a big topic of discussion in the lively office pod, just like the dice-problem. Hormoz started writing simulations to develop a much better grasp on how various controls might behave. This worked out wonderfully, and also served to convince the team that a very simple algorithm for prioritizing traffic could work which Hormoz describes in his post.
Of course, before the simulations, we all started talking about Wikipedia entries of the complicated, cool stuff we could do. The simple simulations showed that none of that was necessary — perfect! There’s tremendous value in exploratory simulation for nebulous tasks that ooze of complexity. It gives a feedback loop, and typically a justification to keep V1 simple.
Do you need to bin-pack tenants on n shards that are being filled up randomly?
Sounds like probabilities over time, a lot of randomness, and smells of
NP-completion. It won’t be long before someone points out deep learning is
perfect, or some resemblance to protein folding or whatever… Write a simple
simulation with a few different sizes and see if you can beat random by even a
little bit. Probably random is fine.
You need to plan for retirement and want to stress-test your portfolio? The state of the art for this is using Monte Carlo analysis which, for the sake of this post, we can say is a fancy way to say “simulate lots of random scenarios.”
I hope you see the value in simulations for getting a handle on these types of problems. I think you’ll also find that writing simulators is some of the most fun programming there is. Enjoy!