How does progress(1) work?
We’ll cover a neat little utility called
progress(1). Many common utilities like
cp or gzip don’t spit out a progress bar by default. progress finds those
processes and estimates how far along they are with their operation. For
example, if you’re copying a 10Gb with cp, running progress will indicate
that it’s progressed 1Gb, and has another 9Gb to go.
Here’s an example, kindly borrowed from the project’s README:
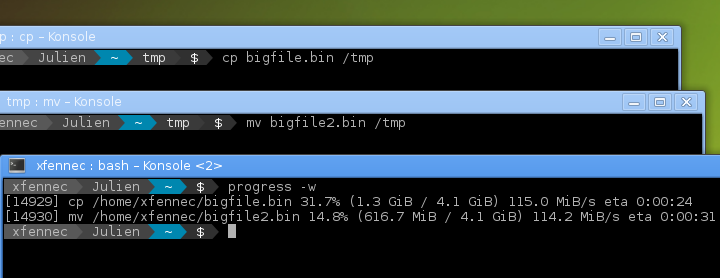
What I was interested in is, how does it work? The README briefly goes
over it, but I wanted to go a little deeper. Fortunately, it’s a fairly simple C
program. While this utility works on MacOS, I’ll cover how it works on Linux.
For MacOS, the methods for obtaining the information about the file-descriptors
and processes is slightly different, utilizing a library called libproc, due
to the absence of the /proc file-system. That’s the depth we’ll cover with
MacOS.
At the heart of progress, we find the function monitor_processes.
On Linux, every process exposes itself as a directory on the file-system in
/proc as /proc/<pid>. In the directory, there’s e.g. the exe file is a
link pointing to the binary that the process is executing, this could be for
example /bin/tar. There’s many other interesting links and files in here. I
open environ regularly in production to check which environment variables a
process has open. Other files will you about its memory usage, various process
configuration, or its priority if the OOM-killer is looking for its next target.
progress will look through the exe links for all processes on the system to
find interesting binaries, like cp, cat, tar, grep, cut, gunzip,
sort, md5sum, and many more.
For each of these processes, it’ll scan every file descriptor the process has
opened through the /proc/<pid>/fd and /proc/<pid>/fdinfo directories. These
contain ample information about the file, such as the name of the file, the
size, what position we’re reading at, and so on. progress will skip file
descriptors that are invalid or are not for files, e.g. a socket.
progress will find the biggest file-descriptor opened by the process, e.g.
whatever cp is copying and see what offset in the file the process is at.
Based on that, the total file size, and waiting a second before doing a second
read it can estimate the process of the process and its throughput.
Once progress has done this for all processes, it’ll either quit or do it all
over again (this only takes a few milliseconds). To the user, this appears as
continues monitoring of the processes’ progress!
Of course, this simple method has its limitations. If you’re copying a lot of
small files, then it won’t help you very much. It could be extended to detect
such programs and monitor them, but it’s certainly not trivial. The way this
works also limits its usability in networks, depending on how the network
program is written. If it streams a file locally as it transfers it, it’ll work
well, but if it loads the whole thing into memory and then transfers it,
progress won’t know what to do. From the documentation, it appears that this
works well for downloads by many browsers. Presumably because they pre-allocate
a large file based on the header of the content-length. progress can then
monitor how far along the offset we are.